近日,中國科學(xué)院合肥物質(zhì)院安光所計算機視覺(jué)團隊在全景場(chǎng)景圖生成研究方面取得新進(jìn)展,提出了一種基于CLIP知識轉移和關(guān)系上下文挖掘的全景場(chǎng)景圖生成方法,相關(guān)研究成果已被信號處理領(lǐng)域的頂級國際會(huì )議IEEE International Conference on Acoustics, Speech and Signal Processing (IEEE聲學(xué)、語(yǔ)音與信號處理國際會(huì )議,ICASSP 2024)接收發(fā)表。
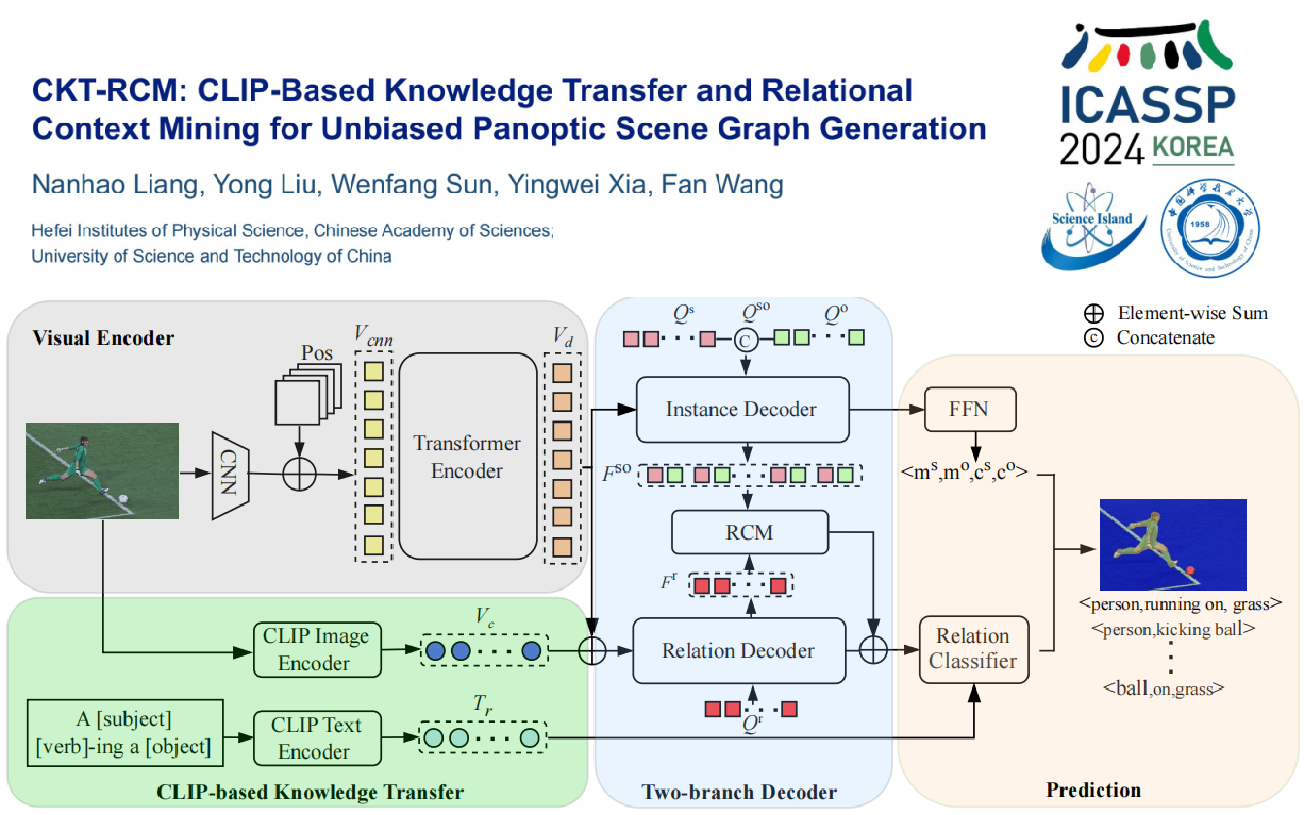
全景場(chǎng)景圖生成(Panoptic Scene Graph,簡(jiǎn)稱(chēng)PSG)是當前場(chǎng)景圖生成(Scene Graph Generation,簡(jiǎn)稱(chēng)SGG)領(lǐng)域中的熱門(mén)研究方向之一,旨在基于圖像的像素級分割信息,利用所有物體及它們之間的成對關(guān)系,進(jìn)行全景場(chǎng)景圖生成表示。然而,由于訓練數據常呈現長(cháng)尾分布,當前PSG方法的預測更傾向于高頻和無(wú)信息的關(guān)系表示(例如“在”、“旁邊”等),導致PSG與實(shí)際應用相距甚遠。
針對上述問(wèn)題,研究人員受人類(lèi)先驗知識的啟發(fā),引入了兩個(gè)新穎的設計:一是使用預訓練的視覺(jué)語(yǔ)言模型來(lái)校正數據傾斜性;二是使用條件先驗分布對上下文關(guān)系進(jìn)行進(jìn)一步的預測質(zhì)量提升。具體而言,研究人員首先從圖像編碼器中提取與關(guān)系相關(guān)的視覺(jué)特征,并通過(guò)從視覺(jué)語(yǔ)言模型的文本編碼器中提取所有關(guān)系的文本嵌入,從而構建關(guān)系分類(lèi)器。之后,利用主客體對之間的豐富關(guān)系上下文信息,通過(guò)交叉注意力機制促進(jìn)上下文的關(guān)系精準預測。最后,研究人員在OpenPSG數據集上進(jìn)行了全面的實(shí)驗,并取得了最先進(jìn)的性能。
博士研究生梁楠昊為論文第一作者,王凡博士后和劉勇研究員為論文通訊作者。該研究工作得到國家重點(diǎn)研發(fā)計劃、國家自然科學(xué)基金、安徽省博士后研究人員科研活動(dòng)經(jīng)費資助項目、合肥物質(zhì)院院長(cháng)基金等項目支持。
文章鏈接:https://doi.org/10.1109/ICASSP48485.2024.10446810